대회기간: 23.05.02 ~ 23.05.18
대회 Task 요약
- 데이터셋은 KLUE 데이터셋으로, 동일 문장 내에서 주어진 단어관의 관계를 예측(Classification)하는 Task
- Relation은 총 30개로, 한정적인 관계만이 주어짐.
대회 데이터셋 분포
Numbers
| Source | Train | Dev | Test | Total |
|---|---|---|---|---|
| Wikipedia | 21,620 | 3,621 | 3,452 | 28,693 |
| Wikitree | 10,672 | 4,088 | 4,249 | 19,009 |
| Policy | 178 | 56 | 64 | 298 |
| Overall | 32,470 | 7,765 | 7,766 | 48,001 |
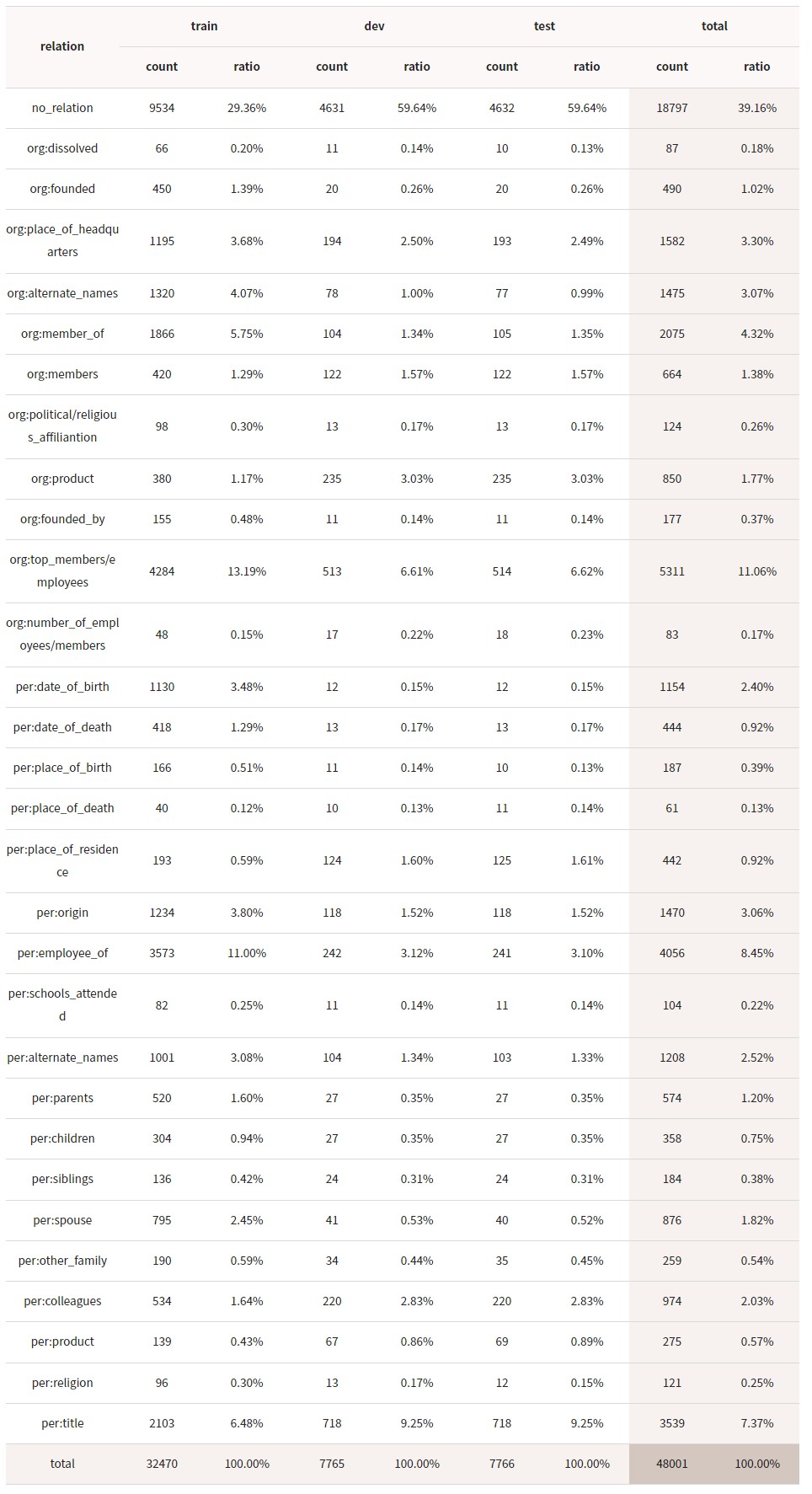
Class 별 분포
대회 수행 과정
1. BaseLine Model 이해
Model :
klue/bert-basePreProcessingsubj_entity+ [SEP] +object_entity+ [SEP] +Sentence
2. 대회 Task의 이해
- 문장 내에서, 두 Entity(
subj,obj)간의 관계를 예측하는 Task - Class Prediction 과 각 클래스별로 예측한 확률값을 도출해내야 함.
- 해볼 수 있는 작업
- Model Change
klue/bert-base->klue/roberta-baseorklue/roberta-largeLoss Function
- Data Augmentation
- Back Translation
- EDA(Easy Data Augmentation)
- Change Preprocessing
- Model Change